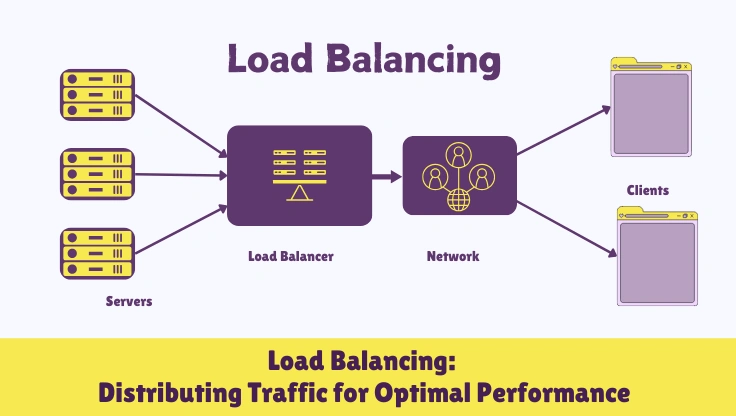
Load Balancing is a critical networking technique that distributes workloads across multiple servers or resources to optimize resource utilization, maximize throughput, minimize response time, and avoid overload. In the context of web services, load balancing is essential for ensuring high availability, scalability, and reliability by evenly distributing incoming network traffic across a pool of servers, making applications more responsive and robust.
Imagine load balancing as a traffic controller for your website or application. It's like having a smart director that evenly distributes incoming requests across a team of servers, rather than overwhelming a single server with all the traffic. Load balancing ensures that no single server bears too much load, preventing bottlenecks and improving overall performance. It's crucial for websites and applications that experience high traffic volumes or require high availability. By distributing requests, load balancing enhances responsiveness, reduces latency, and improves the user experience. It also allows for easier scaling of infrastructure; when traffic increases, more servers can be added to the load-balanced pool to handle the additional load. Load balancing is a cornerstone of modern web architecture, essential for maintaining website performance and reliability under varying traffic conditions.
- Distributing Workloads Across Multiple Servers:
Load balancing is fundamentally about distributing network traffic or application workloads across multiple servers, computing resources, or network links. This distribution aims to prevent any single resource from becoming overloaded and to optimize the use of available resources.
- Optimizing Resource Utilization and Performance:
By evenly distributing workloads, load balancing ensures that all servers in a pool are utilized efficiently. This leads to improved resource utilization, higher throughput, and faster response times for applications and services. Load balancing enhances overall system performance and efficiency.
- Ensuring High Availability, Scalability, and Reliability:
Load balancing is a key component in building highly available, scalable, and reliable systems. It enhances availability by distributing traffic across multiple servers, so if one server fails, others can take over. It enables scalability by allowing easy addition of servers to handle increased load. It improves reliability by reducing the risk of single points of failure and ensuring consistent service performance.
1.1. Types of Load Balancing Methods and Algorithms: Distribution Strategies
Load balancing employs various methods and algorithms to distribute traffic effectively. Understanding these strategies is crucial for choosing the right approach for different scenarios.
Let's explore the common load balancing methods and algorithms, understanding how each approach distributes traffic and their respective advantages and use cases:
- Round Robin: Simple Sequential Distribution:
- Distributing Requests Sequentially to Servers:
Round Robin is one of the simplest load balancing algorithms. It distributes incoming requests sequentially to each server in the server pool in a circular order. Each new request is assigned to the next server in the list, and after the last server, it cycles back to the first one. Round Robin is easy to implement and understand.
- Equal Distribution, Regardless of Server Load:
Round Robin provides equal distribution of requests across servers, regardless of the current load or capacity of each server. It does not consider server health, response time, or resource utilization. It assumes all servers are equally capable and available.
- Suitable for Homogeneous Server Environments:
Round Robin is best suited for environments where servers are homogeneous, meaning they have similar configurations and capacities, and handle requests with roughly the same processing time. It is less effective in environments with heterogeneous servers or varying server loads.
- Least Connections: Directing Traffic to Least Loaded Servers:
- Routing Requests to Server with Fewest Active Connections:
Least Connections algorithm directs incoming requests to the server with the fewest active connections at that moment. It monitors the number of active connections on each server and selects the server with the lowest count. Least Connections aims to distribute load based on the current server workload.
- Dynamic Load Consideration, Adapting to Server Capacity:
Least Connections is a dynamic load balancing method that takes into account the current server load. It adapts to varying server capacities and traffic patterns, directing more requests to servers that are less busy. It is more effective than Round Robin in heterogeneous environments or when server loads vary.
- Effective for Session-Based Applications:
Least Connections is particularly effective for session-based applications where maintaining session persistence is important. By directing subsequent requests from the same session to the same least-loaded server, it helps maintain session affinity and improve user experience.
- Weighted Round Robin: Prioritizing Servers Based on Weight:
- Assigning Weights to Servers Based on Capacity:
Weighted Round Robin is an enhanced version of Round Robin that allows assigning weights to each server based on its capacity or priority. Servers with higher weights receive proportionally more requests than servers with lower weights. Weights can be based on server processing power, memory, or network bandwidth.
- Distributing Traffic Proportionally to Server Weights:
Weighted Round Robin distributes traffic proportionally to the assigned weights. For example, a server with a weight of 2 will receive twice as many requests as a server with a weight of 1. This method allows administrators to prioritize more powerful servers or allocate resources based on server capabilities.
- Suitable for Heterogeneous Server Pools:
Weighted Round Robin is well-suited for heterogeneous server environments where servers have different capacities. It enables administrators to optimize resource utilization by directing more traffic to more capable servers and less traffic to less powerful ones. It provides more granular control over traffic distribution compared to simple Round Robin.
- IP Hash: Consistent Hashing Based on Client IP Address:
- Hashing Client IP to Map to a Specific Server:
IP Hash algorithm uses a hash function to map the client's IP address to a specific server in the server pool. All requests from the same client IP address are consistently directed to the same server. IP Hash ensures session persistence based on the client's IP address.
- Ensuring Session Persistence Based on Client IP:
IP Hash is primarily used to maintain session persistence or session affinity. By consistently routing requests from the same client IP to the same server, it ensures that user sessions are maintained on the same server throughout their interaction. This is important for applications that rely on server-side session state.
- Limited Load Balancing, Potential for Uneven Distribution:
IP Hash is not primarily designed for optimal load balancing. It may lead to uneven distribution of traffic if client IP addresses are not evenly distributed across the server pool. Clients from the same network or subnet may be directed to the same server, potentially causing imbalances. IP Hash is more focused on session persistence than load balancing efficiency.
- URL Hash: Distributing Based on URL or URI:
- Hashing the URL or URI to Select a Server:
URL Hash algorithm uses a hash function to map the requested URL or URI to a specific server. Requests for the same URL or URI are consistently directed to the same server. URL Hash can be used for content-based load balancing or caching purposes.
- Content-Based Distribution, Caching Efficiency:
URL Hash can be used for content-based distribution, where requests for specific types of content are directed to servers optimized for handling that content. It can also improve caching efficiency by directing requests for the same URL to the same server, increasing cache hit rates. URL Hash can be combined with content delivery networks (CDNs) for efficient content distribution.
- Complexity in Implementation, Less Dynamic Load Balancing:
URL Hash can be more complex to implement compared to simpler algorithms like Round Robin or Least Connections. It is less dynamic in terms of load balancing, as it primarily focuses on content-based distribution rather than real-time server load. URL Hash may require careful configuration to ensure even distribution and avoid hotspots for popular URLs.
- Agent-Based (Adaptive) Load Balancing: Real-Time Server Monitoring:
- Using Agents to Monitor Server Load and Performance:
Agent-Based Load Balancing, also known as Adaptive Load Balancing, uses software agents installed on each server to monitor real-time server load, performance metrics (CPU usage, memory utilization, response time), and health status. The load balancer uses this information to make intelligent routing decisions.
- Dynamic and Intelligent Traffic Distribution:
Agent-Based Load Balancing is highly dynamic and intelligent. It adapts to changing server conditions in real-time, directing traffic to servers that are healthy, responsive, and have available capacity. It provides the most sophisticated and efficient load distribution compared to static algorithms.
- Optimal Performance, High Availability, Complex Setup:
Agent-Based Load Balancing offers optimal performance and high availability by continuously optimizing traffic distribution based on server conditions. However, it is more complex to set up and manage compared to simpler algorithms, as it requires agent deployment, monitoring infrastructure, and dynamic decision-making logic. Agent-Based Load Balancing is often used in large-scale, mission-critical environments where performance and availability are paramount.
Choosing the appropriate load balancing method depends on factors such as the application type, server environment, traffic patterns, session persistence requirements, and performance goals. Organizations often use a combination of load balancing techniques to achieve optimal performance, availability, and scalability for their web services.
Server Hardware refers to the physical components that constitute a server, which are essential for load balancing and overall web infrastructure performance. The choice of server hardware significantly impacts the capacity, speed, reliability, and efficiency of load balancing solutions and the applications they support. Selecting appropriate server hardware is a critical decision in designing robust and scalable web architectures.
Imagine server hardware as the physical foundation upon which load balancing and web services are built. It's like the engine and chassis of a car – the underlying components that determine performance, capacity, and reliability. In the context of load balancing, server hardware includes the physical servers that form the server pool behind the load balancer. The specifications of these servers – their processors, memory, storage, and network interfaces – directly impact how effectively they can handle distributed workloads. Powerful server hardware ensures that each server can process a significant share of the traffic, respond quickly to requests, and maintain stability under load. The right server hardware is crucial for realizing the benefits of load balancing, ensuring that web applications are fast, responsive, and always available to users. It's the tangible infrastructure that makes digital services possible.
- Physical Components of a Server System:
Server hardware encompasses all the physical parts that make up a server, including processors (CPUs), memory (RAM), storage devices (HDDs, SSDs), network interface cards (NICs), motherboards, power supplies, and cooling systems. These components work together to provide the computing resources needed to run server software and handle workloads.
- Essential for Load Balancing and Web Infrastructure:
Server hardware is the foundation for load balancing infrastructure. The performance and capabilities of server hardware directly affect the efficiency and effectiveness of load balancing solutions. Load balancers distribute traffic to these physical servers, which then process the requests. Adequate server hardware is crucial for handling distributed workloads and maintaining service performance.
- Impacting Capacity, Speed, Reliability, and Efficiency:
The choice of server hardware has a profound impact on server capacity (how much workload it can handle), processing speed (how quickly it can execute tasks), reliability (how consistently it operates without failures), and energy efficiency. Selecting appropriate server hardware is vital for achieving desired performance levels, scalability, and operational efficiency in web environments.
2.1. Key Server Hardware Components and Considerations: Selecting the Right Infrastructure
When choosing server hardware for load balancing, several key components and considerations come into play. These factors determine the overall performance and suitability of servers for handling distributed workloads.
Let's explore the key server hardware components and considerations, understanding their roles and how to select the right infrastructure for load balancing:
- Processors (CPUs): Processing Power and Cores:
- Number of Cores, Clock Speed, and Architecture:
Processors (CPUs) are the brains of servers, responsible for executing instructions and processing data. Key CPU specifications include the number of cores (processing units), clock speed (processing frequency), and architecture (e.g., Intel Xeon, AMD EPYC). More cores and higher clock speeds generally mean better processing power. Server CPUs are designed for heavy workloads and continuous operation.
- Impact on Request Processing Speed and Concurrency:
CPU performance directly impacts how quickly servers can process incoming requests and handle concurrent connections. For load balancing, servers need to efficiently process requests distributed by the load balancer. Sufficient CPU power is crucial for handling high traffic volumes and complex application logic. Multi-core processors are essential for parallel processing and handling concurrent requests.
- Consider Workload Type: CPU-Intensive vs. I/O-Intensive:
The type of workload influences CPU requirements. CPU-intensive applications (e.g., video encoding, complex calculations) demand high processing power, while I/O-intensive applications (e.g., database servers, file servers) may be more dependent on storage and network performance. Choose CPUs based on the primary workload characteristics. For web servers, a balance of CPU and I/O performance is typically needed.
- Memory (RAM): Data Access Speed and Capacity:
- Amount of RAM, Speed, and Type (DDR4, DDR5):
Memory (RAM) provides fast, temporary storage for data that the CPU needs to access quickly. Key RAM specifications include the amount of RAM (capacity in GB or TB), speed (data transfer rate), and type (e.g., DDR4, DDR5). More RAM and faster RAM improve data access speed and overall system performance. Server RAM is designed for high reliability and error correction (ECC).
- Buffering and Caching Data for Faster Access:
RAM is used for buffering and caching frequently accessed data, reducing the need to retrieve data from slower storage devices. For load balancing, sufficient RAM ensures that servers can quickly access application code, session data, and cached content, improving response times. RAM capacity should be sized based on the application's memory footprint and expected workload.
- Impact on Application Responsiveness and Multitasking:
Adequate RAM is crucial for application responsiveness and efficient multitasking. Insufficient RAM can lead to performance bottlenecks, disk swapping, and slow response times. Servers need enough RAM to handle concurrent requests, run server software, and cache data effectively. RAM capacity should be scaled to accommodate peak traffic and application demands.
- Storage Devices: Speed, Capacity, and Redundancy:
- HDDs vs. SSDs: Speed and Latency Trade-offs:
Storage devices store operating systems, applications, and data persistently. Hard Disk Drives (HDDs) offer high capacity at lower cost but have slower access speeds and higher latency. Solid State Drives (SSDs) provide significantly faster access speeds and lower latency but are typically more expensive per GB. NVMe SSDs offer even higher performance than SATA SSDs. The choice between HDDs and SSDs depends on performance requirements and budget.
- Storage Capacity, RAID Configurations for Data Protection:
Storage capacity should be sufficient to store application data, logs, and backups. RAID (Redundant Array of Independent Disks) configurations are used for data protection and redundancy. RAID levels like RAID 1 (mirroring), RAID 5 (striping with parity), and RAID 10 (mirroring and striping) provide data redundancy and fault tolerance. RAID protects against data loss in case of drive failures.
- Consider Data Access Patterns: Read-Intensive vs. Write-Intensive:
Data access patterns influence storage device selection. Read-intensive applications (e.g., content delivery, web servers) benefit from fast read speeds of SSDs. Write-intensive applications (e.g., database servers, logging systems) may require high write endurance and performance. Choose storage devices based on application data access patterns and performance requirements.
- Network Interface Cards (NICs): Bandwidth and Connectivity:
- Network Bandwidth, Interface Type (Gigabit Ethernet, 10GbE, etc.):
Network Interface Cards (NICs) enable servers to connect to networks and communicate with clients and other servers. Key NIC specifications include network bandwidth (data transfer rate in Gbps or Mbps) and interface type (e.g., Gigabit Ethernet, 10 Gigabit Ethernet, 40 Gigabit Ethernet). Higher bandwidth NICs provide faster network communication and higher throughput. Server NICs often support advanced features like link aggregation and VLANs.
- Redundancy and Load Balancing at Network Level:
Redundant NICs and network interfaces provide network fault tolerance. Link aggregation (LAG) combines multiple NICs into a single logical interface, increasing bandwidth and providing redundancy. Load balancing can also be implemented at the network level using techniques like NIC teaming or load balancing switches. Network redundancy and load balancing enhance network availability and performance.
- Impact on Data Transfer Rates and Latency:
NIC performance directly impacts data transfer rates and network latency. For load balancing, high-bandwidth, low-latency NICs are essential for handling high traffic volumes and ensuring fast response times. Network infrastructure, including switches and routers, should also support the required bandwidth and low latency. Network performance is critical for overall load balancing effectiveness.
- Redundancy and Failover: Ensuring High Availability:
- Redundant Power Supplies, Cooling, and Network Paths:
Server hardware redundancy is crucial for ensuring high availability and fault tolerance. Redundant power supplies protect against power failures. Redundant cooling systems prevent overheating. Redundant network paths (dual NICs, redundant switches) provide network connectivity failover. Redundancy minimizes single points of failure and improves system uptime.
- Hot-Swappable Components for Maintenance and Upgrades:
Hot-swappable components, such as hard drives, power supplies, and fans, allow for maintenance and upgrades without powering down the server. Hot-swapping minimizes downtime during hardware replacements or upgrades. It is essential for maintaining continuous operation in load-balanced environments.
- Failover Mechanisms: Automatic Switchover in Case of Failure:
Failover mechanisms ensure automatic switchover to redundant components or servers in case of hardware failures. Load balancers themselves often have redundancy and failover capabilities. Server clustering and virtualization technologies also provide failover options. Failover mechanisms are critical for maintaining high availability and service continuity in load-balanced systems.
- Form Factor and Rack Density: Space and Scalability Considerations:
- Rack Servers, Blade Servers, and Density Optimization:
Server form factor (physical size and shape) and rack density impact space utilization and scalability. Rack servers are standard 1U, 2U, or 4U servers designed to be mounted in server racks. Blade servers are high-density servers that fit into blade enclosures, maximizing rack density. Density-optimized servers are designed for environments where space is limited. Server form factor and density should be considered based on data center space and scalability requirements.
- Data Center Space, Power, and Cooling Requirements:
Server hardware choices affect data center space, power consumption, and cooling requirements. High-density servers may require more power and cooling per rack unit. Data center infrastructure, including power distribution, cooling systems, and rack space, must be planned to accommodate server hardware requirements. Power efficiency and cooling efficiency are important considerations for operational costs and environmental impact.
- Scalability for Future Growth and Expansion:
Server hardware selection should consider scalability for future growth and expansion. Choose server platforms that can be easily upgraded or scaled out as demand increases. Modular server designs, virtualization, and cloud-based infrastructure provide scalability and flexibility. Scalability planning is essential for adapting to changing workload demands and business growth.
Careful consideration of these server hardware components and factors is essential for building robust and efficient load balancing infrastructures. The right server hardware ensures that load balancing solutions can deliver optimal performance, high availability, and scalability to meet the demands of modern web applications and services.
Redundancy in load balancing is a critical aspect of high availability and fault tolerance, involving the duplication of critical components and systems to ensure continuous operation in case of failures. In load balancing, redundancy is implemented at various levels – load balancers, servers, network paths, and data centers – to eliminate single points of failure and maintain uninterrupted service availability.
Imagine redundancy in load balancing as having backup systems at every critical point to ensure that services keep running even if something fails. It's like having a spare tire for your car, backup generators for electricity, and multiple routes to your destination. In load balancing, redundancy means having duplicate load balancers, server instances, network connections, and even entire data centers. If a primary load balancer fails, a backup takes over seamlessly. If a server goes down, others in the pool continue to handle traffic. Redundant network paths ensure connectivity even if one path is disrupted. Data center redundancy provides disaster recovery capabilities in case of major outages. Redundancy is the safety net of load balancing, ensuring that websites and applications remain available and operational even in the face of hardware failures, network issues, or disasters. It's the key to achieving true high availability and business continuity.
- Duplication of Critical Components for Fault Tolerance:
Redundancy involves duplicating critical components and systems in a load balancing infrastructure to provide backup and failover capabilities. This duplication ensures that if one component fails, a redundant component can immediately take over, minimizing service disruption. Redundancy is a fundamental principle of fault tolerance and high availability.
- Eliminating Single Points of Failure (SPOF):
The primary goal of redundancy is to eliminate single points of failure (SPOFs) in the load balancing architecture. SPOFs are components whose failure can cause the entire system to fail. Redundancy ensures that there are no single components that can bring down the entire load balancing setup or the services it supports. Eliminating SPOFs is crucial for achieving high availability.
- Maintaining Uninterrupted Service Availability:
Redundancy is essential for maintaining uninterrupted service availability in load-balanced environments. By providing failover and backup mechanisms, redundancy ensures that services remain accessible to users even during hardware failures, software issues, network disruptions, or planned maintenance. High availability is a key benefit of redundancy in load balancing.
3.1. Redundancy Strategies in Load Balancing: Levels and Implementation Approaches
Redundancy in load balancing can be implemented at various levels and using different strategies. Understanding these levels and approaches helps in designing comprehensive redundancy plans.
Let's explore the key redundancy strategies in load balancing, understanding the levels at which redundancy is implemented and the common approaches used:
- Load Balancer Redundancy (Active-Passive, Active-Active):
- Active-Passive Redundancy: Failover Load Balancer:
Active-Passive Load Balancer Redundancy involves deploying two load balancers: one active and one passive (standby). The active load balancer handles all traffic under normal conditions. The passive load balancer is in standby mode, continuously monitoring the active load balancer's health. In case of active load balancer failure, the passive load balancer automatically takes over, becoming the new active load balancer. Active-passive redundancy provides failover capability.
- Active-Active Redundancy: Distributed Load Balancing:
Active-Active Load Balancer Redundancy involves deploying multiple active load balancers simultaneously. All active load balancers actively distribute traffic concurrently. Active-active setup increases overall load balancing capacity and provides redundancy. If one active load balancer fails, the others continue to operate, distributing the load among the remaining active load balancers. Active-active redundancy enhances both performance and availability.
- Health Checks and Automatic Failover Mechanisms:
Load balancer redundancy relies on health checks to monitor the status of active load balancers and automatic failover mechanisms to initiate switchover to standby load balancers or redistribute traffic among active load balancers in case of failures. Health checks continuously verify the health and availability of load balancers. Failover mechanisms ensure seamless transition and minimal service disruption during load balancer failures.
- Server Redundancy: Server Pools and Clustering:
- Server Pools: Multiple Servers Behind Load Balancer:
Server Pools are fundamental to server redundancy in load balancing. Instead of relying on a single server, load balancers distribute traffic across a pool of multiple servers. If one server in the pool fails, the load balancer automatically detects the failure through health checks and stops sending traffic to the failed server. Traffic is redistributed among the remaining healthy servers in the pool. Server pools provide inherent redundancy and scalability.
- Server Clustering: Grouping Servers for High Availability:
Server Clustering involves grouping multiple servers together to work as a single system for high availability and fault tolerance. Server clusters can be active-passive or active-active. In active-passive clusters, one server is active, and others are in standby. In active-active clusters, all servers are active and share the workload. Server clustering enhances redundancy and provides seamless failover in case of server failures. Load balancers often distribute traffic to server clusters.
- Horizontal Scaling: Adding More Servers to Pool:
Horizontal Scaling is a key aspect of server redundancy and scalability. When demand increases or server capacity needs to be expanded, more servers can be easily added to the server pool behind the load balancer. Load balancers automatically detect and incorporate new servers into the traffic distribution. Horizontal scaling allows for flexible and cost-effective capacity expansion, ensuring that the system can handle growing workloads while maintaining redundancy.
- Network Path Redundancy: Multiple Network Connections:
- Dual Network Paths, Multiple ISPs, Link Aggregation:
Network Path Redundancy involves having multiple network paths to ensure network connectivity even if one path fails. This can include dual network paths, connections to multiple Internet Service Providers (ISPs), and link aggregation (LAG) to combine bandwidth and provide link redundancy. Redundant network paths protect against network outages and ISP failures.
- Avoiding Network Outages and ISP Failures:
Network path redundancy is crucial for avoiding network outages and ISP failures that can disrupt service availability. If the primary network path fails, traffic can automatically failover to the secondary path, maintaining network connectivity. Multiple ISP connections provide redundancy against ISP-specific outages. Link aggregation provides link-level redundancy and increased bandwidth.
- Redundant Network Devices: Switches, Routers, Firewalls:
Redundancy should also be implemented in network devices, such as switches, routers, and firewalls. Redundant network devices ensure that network infrastructure components do not become single points of failure. Hot Standby Router Protocol (HSRP) and Virtual Router Redundancy Protocol (VRRP) are used to provide router redundancy. Firewall clustering provides firewall redundancy. Redundant network devices enhance overall network resilience.
- Data Center Redundancy (Geographic Redundancy):
- Deploying Infrastructure in Multiple Geographic Locations:
Data Center Redundancy, also known as Geographic Redundancy, involves deploying load balancing infrastructure and servers in multiple geographically separated data centers. Geographic redundancy protects against data center-level failures, such as power outages, natural disasters, or regional network issues. If one data center becomes unavailable, services can failover to another data center.
- Disaster Recovery and Business Continuity:
Data center redundancy is a key component of disaster recovery and business continuity plans. It ensures that organizations can recover from major disasters and maintain business operations with minimal downtime. Data replication and synchronization between data centers are essential for data consistency and failover capabilities. Disaster recovery drills and testing are important to validate data center redundancy effectiveness.
- Active-Active and Active-Standby Data Center Configurations:
Data center redundancy can be implemented in active-active or active-standby configurations. In active-active data center redundancy, both data centers are active and serve traffic concurrently. In active-standby data center redundancy, one data center is active, and the other is in standby for failover. Active-active data center setups provide better resource utilization and faster failover but are more complex to manage. Active-standby setups are simpler but may have longer failover times.
- Power and Cooling Redundancy: Infrastructure Reliability:
- Redundant Power Supplies (UPS), Generators:
Power Redundancy is crucial for server and data center reliability. Redundant power supplies in servers protect against power supply failures. Uninterruptible Power Supplies (UPS) provide backup power during short power outages. Generators provide extended backup power during prolonged outages. Power redundancy ensures continuous power supply to critical infrastructure components.
- Redundant Cooling Systems, HVAC, Temperature Control:
Cooling Redundancy is essential for preventing server overheating and ensuring hardware reliability. Redundant cooling systems, HVAC (Heating, Ventilation, and Air Conditioning) units, and temperature control mechanisms maintain optimal operating temperatures in data centers and server rooms. Cooling redundancy prevents server downtime due to overheating and ensures stable hardware performance.
- Environmental Monitoring and Alerting Systems:
Environmental Monitoring and Alerting Systems are used to monitor power, temperature, humidity, and other environmental factors in data centers and server rooms. These systems provide early warnings of potential environmental issues, such as power fluctuations, overheating, or cooling system failures. Proactive monitoring and alerting enable timely intervention to prevent environmental-related outages.
Implementing redundancy at these various levels creates a layered and robust load balancing infrastructure that can withstand failures and maintain continuous service availability. A comprehensive redundancy strategy is essential for organizations that require high uptime and business continuity for their web applications and online services.